
訳あってX(Twitter)で自分のすべてのツイートを取得する必要がでてきました。
通常であればTwitter APIを使ってサクッと取得したいところなのですが、悲しいことにTwitter APIは2023年に大幅な仕様変更が行われ、Freeプランではツイートの取得ができなくなりました。
ツイートの取得ができる最小プランがBasicプランですが、これは月100$とお高めです。趣味だけで使うには払いたくありませんね。
ということで仕方がないので代替案を考えてみました。
(そういえば今は「ツイート」じゃなくて「ポスト」って呼ぶんでしたっけ…。めんどくさい…。)
1. アーカイブのダウンロード
面倒ですがまずはブラウザでポチポチ操作が必要です。
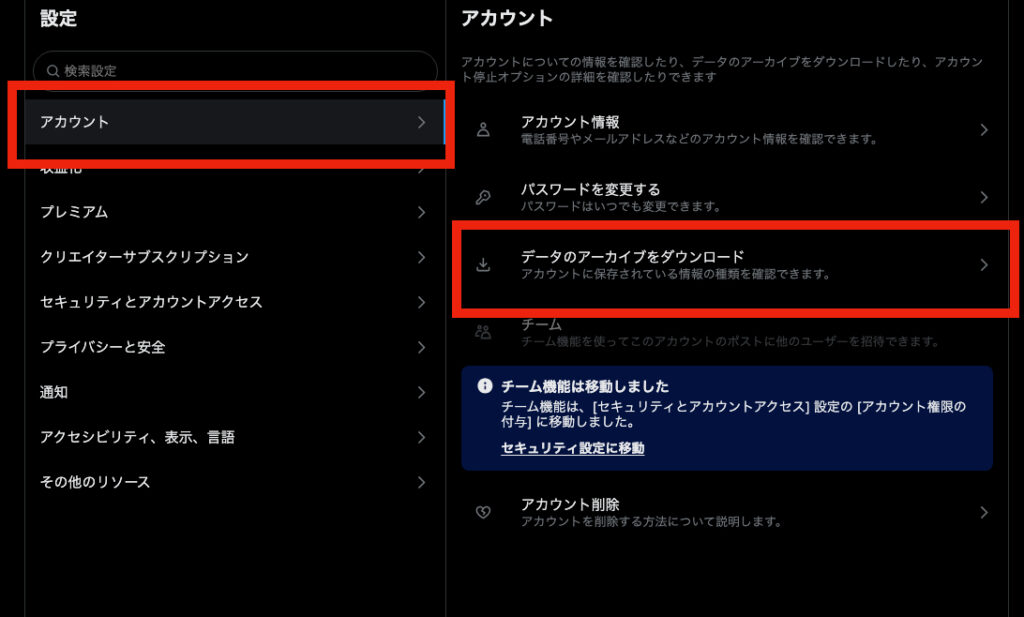
X(Twitter)の設定ページ(https://twitter.com/settings/account)へ移動し、「アカウント」>「データのアーカイブをダウンロード」を選択します。
ここからダウンロードのリクエストを送ることができます。
リクエストを送ったらX側の準備ができるまで1日程度かかるので、気長に待ちましょう。
ダウンロードできるようになったらメールで通知が来ますので、メールの指示に従ってダウンロードしましょう。
2. tweets.jsをtweets.jsonへ変換
さっそくダウンロードファイルを解凍してみましょう。
ファイルが多数含まれていますが、今回欲しい過去のツイートデータは/data/tweets.jsにあります。
tweets.jsの中身はこんな感じ↓
window.YTD.tweets.part0 = [
{
"tweet" : {
"edit_info" : {...},
"retweeted" : false,
"source" : "...",
"entities" : {...},
"display_text_range" : [
"0",
"83"
],
"favorite_count" : "...",
"id_str" : "...",
"truncated" : false,
"retweet_count" : "...",
"id" : "...",
"possibly_sensitive" : false,
"created_at" : "Fri Dec 29 10:12:14 +0000 2023",
"favorited" : false,
"full_text" : "ガンボスープめちゃくちゃ美味かった",
"lang" : "ja"
}
},
{
"tweet" : {
...
}
}
]このファイルは、window.YTD.tweets.part0というobjectに過去のツイートがリスト形式で格納されているシンプルなファイルです。
今回はこのファイルの中身にしか用がないので、次のように"window.YTD.tweets.part0 = "の部分を消して、扱いやすいjsonファイルにしちゃいましょう。(拡張子も".json"に変えるだけ)。
[
{
"tweet" : {
"edit_info" : {...},
"retweeted" : false,
"source" : "...",
"entities" : {...},
"display_text_range" : [
"0",
"83"
],
"favorite_count" : "...",
"id_str" : "...",
"truncated" : false,
"retweet_count" : "...",
"id" : "...",
"possibly_sensitive" : false,
"created_at" : "Fri Dec 29 10:12:14 +0000 2023",
"favorited" : false,
"full_text" : "ガンボスープめちゃくちゃ美味かった",
"lang" : "ja"
}
},
{
"tweet" : {
...
}
}
]3. データ抽出
先ほど作ったtweets.jsonはシンプルなjsonファイルなので、PythonなりJavascriptなりで簡単にパースできます。
今回の目的は、ここからツイートのテキストのみを取り出してリストにすることです。
Pythonだと以下のようにできます。
import json
# 元ファイル読み込み
with open('tweets.json') as f:
input_json = json.load(f)
# 元のリストから"full_text"のみを抽出したリストを生成
# (リツイートは除く)
output_json = [tweet["tweet"]["full_text"] for tweet in input_json if len(tweet["tweet"]["entities"]["user_mentions"]) == 0]
# ファイルに保存
with open('tweetFullTexts.json', 'w') as f:
json.dump(output_json, f, indent=2, ensure_ascii=False)元のファイルには"full_text"フィールドにツイートの内容がstringで格納されているので、そこだけを取り出してリストを作っています。
ちなみにリツイートか否かは"user_mentions"の有無で判別しています。
("retweeted"フィールドはリツイートか否かには関係ないみたいです。これ何のためのフィールドなんだろ…)
最終的な出力ファイルは以下のような感じになります。
[
"ガンボスープめちゃくちゃ美味かった",
"Leafletバグ多すぎてつらい",
"リメンバーミーのエンディングは神"
]

コメント